70 Fitting and interpreting models
You can follow along with the slides here if you would like to open them full-screen.
70.2 A More Technical Worked Example
Let’s load our standard libraries:
If you’ve taken a regression course, you might recognize this model as a special case of a linear model.
If you haven’t, well, it doesn’t really matter much except… we can use the
lm()function to fit the model.
The advantage is that lm() easily splits the data into fitted values and residuals:
Observed value = Fitted value + residual
Let’s get the fitted values and residuals for each voice part:
We can extract the fitted values using fitted.values(lm_singer) and the residuals with residuals(lm_singer) or lm_singer$residuals.
For convenience, we create a data frame with two columns: the voice parts and the residuals.
We can also do this with group_by and mutate:
fits <- singer %>%
group_by(voice.part) %>%
mutate(
fit = mean(height),
residual = height - mean(height)
)70.2.1 Does the linear model fit?
To assess whether the linear model is a good fit to the data, we need to know whether the errors look like they come from normal distributions with the same variance.
The residuals are our estimates of the errors, and so we need to check both homoscedasticity and normality.
70.2.2 Homoscedasticity
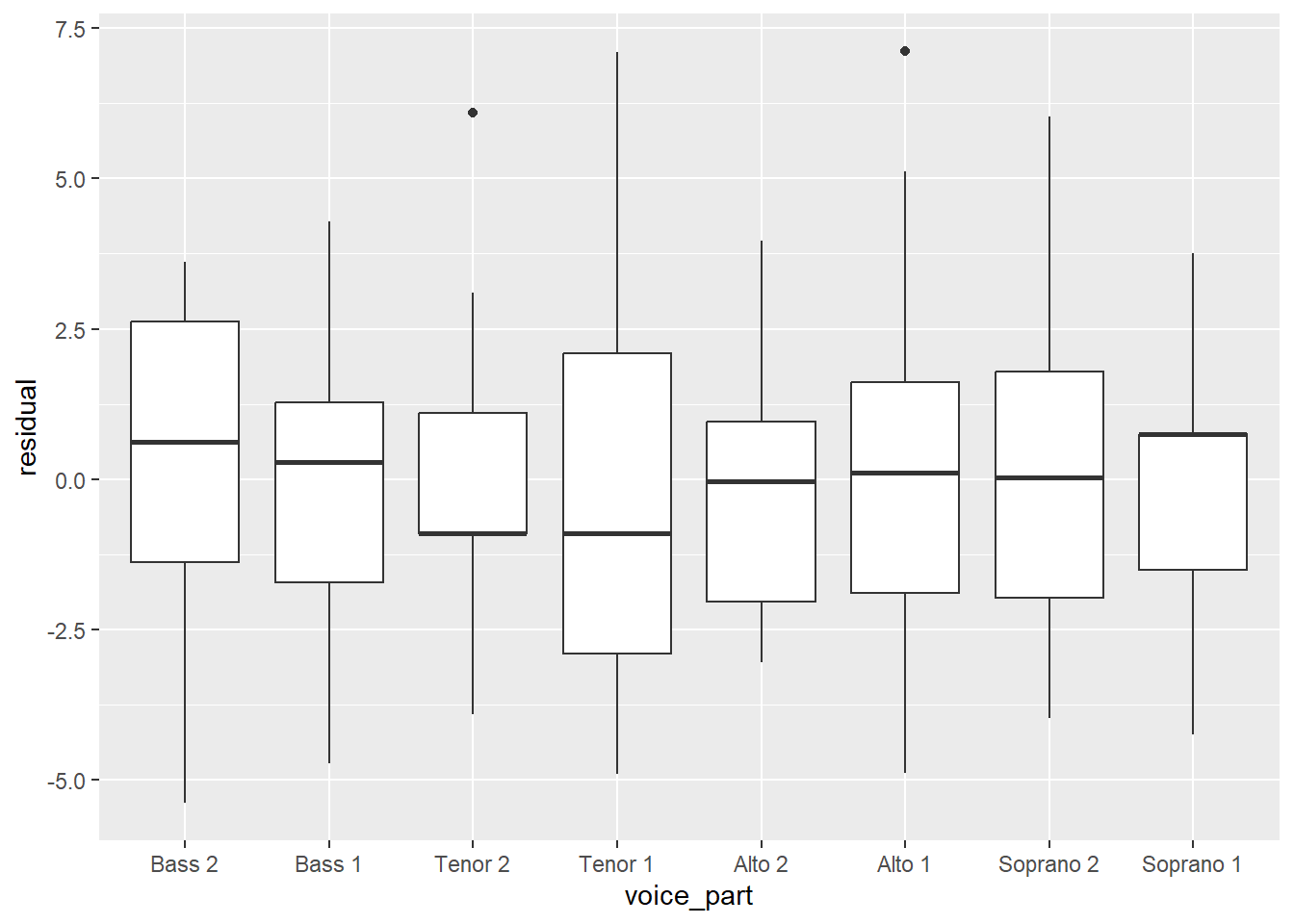
Homoscedasticity, or homogeneity of variances, is a modeling assumption that we make that assummes we have equal or similar variances in different groups being compared. In other words, the variance of the residuals should be the same for all values of the predictor. We can check this by looking at the residuals for each voice part.
There are a few ways we can look at the residuals. Side-by-side boxplots give a broad overview:
We can also look at the ecdfs of the residuals for each voice part.
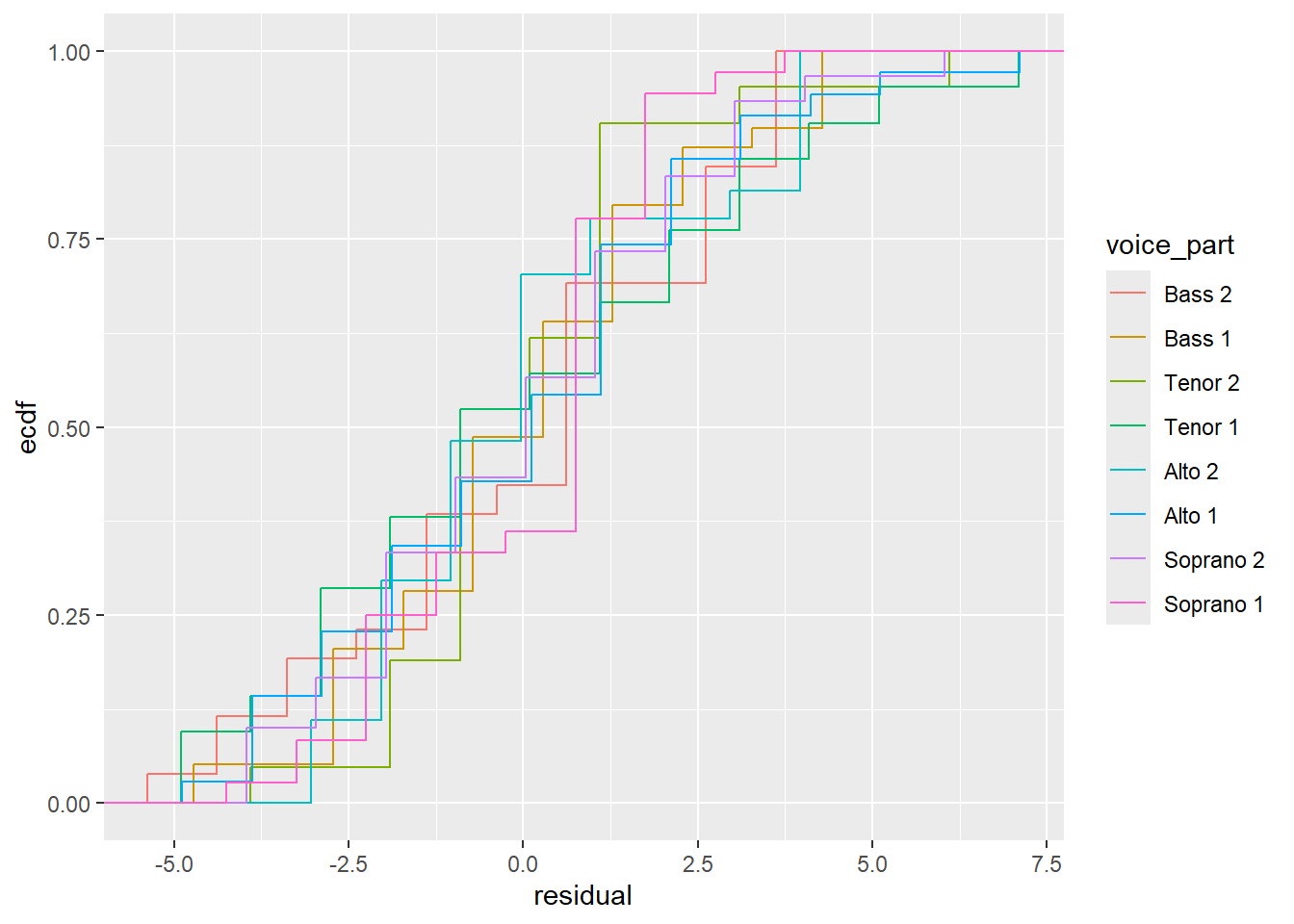
From these plots, it seems like the residuals in each group have approximately the same variance.
70.2.3 Normality
Normality of the residuals is another important assumption of the linear model. We can check this assumption by looking at normal QQ plots of the residuals for each voice part. We can do this by faceting, which will allow us to examine each voice part separately. We can use the stat_qq() function to create the QQ plots.:
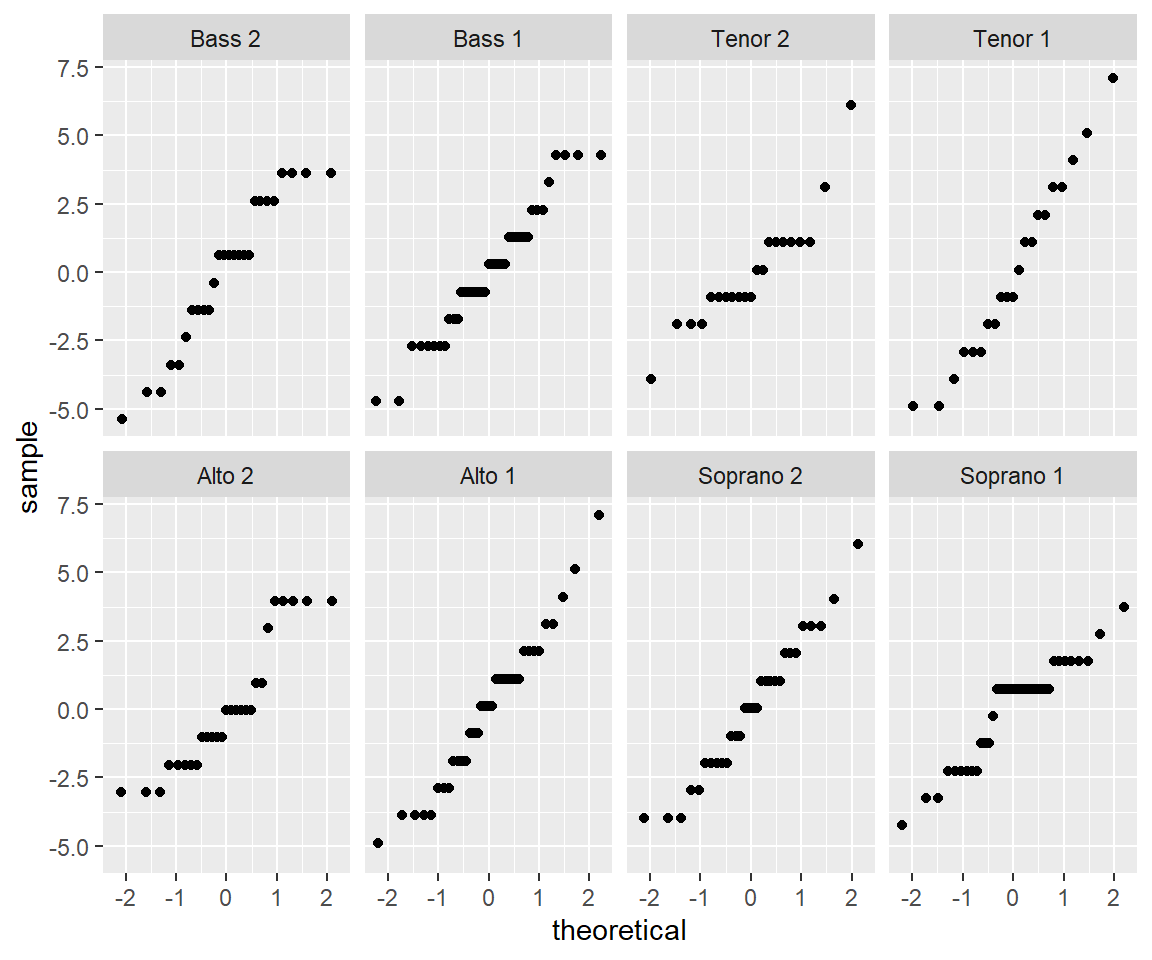
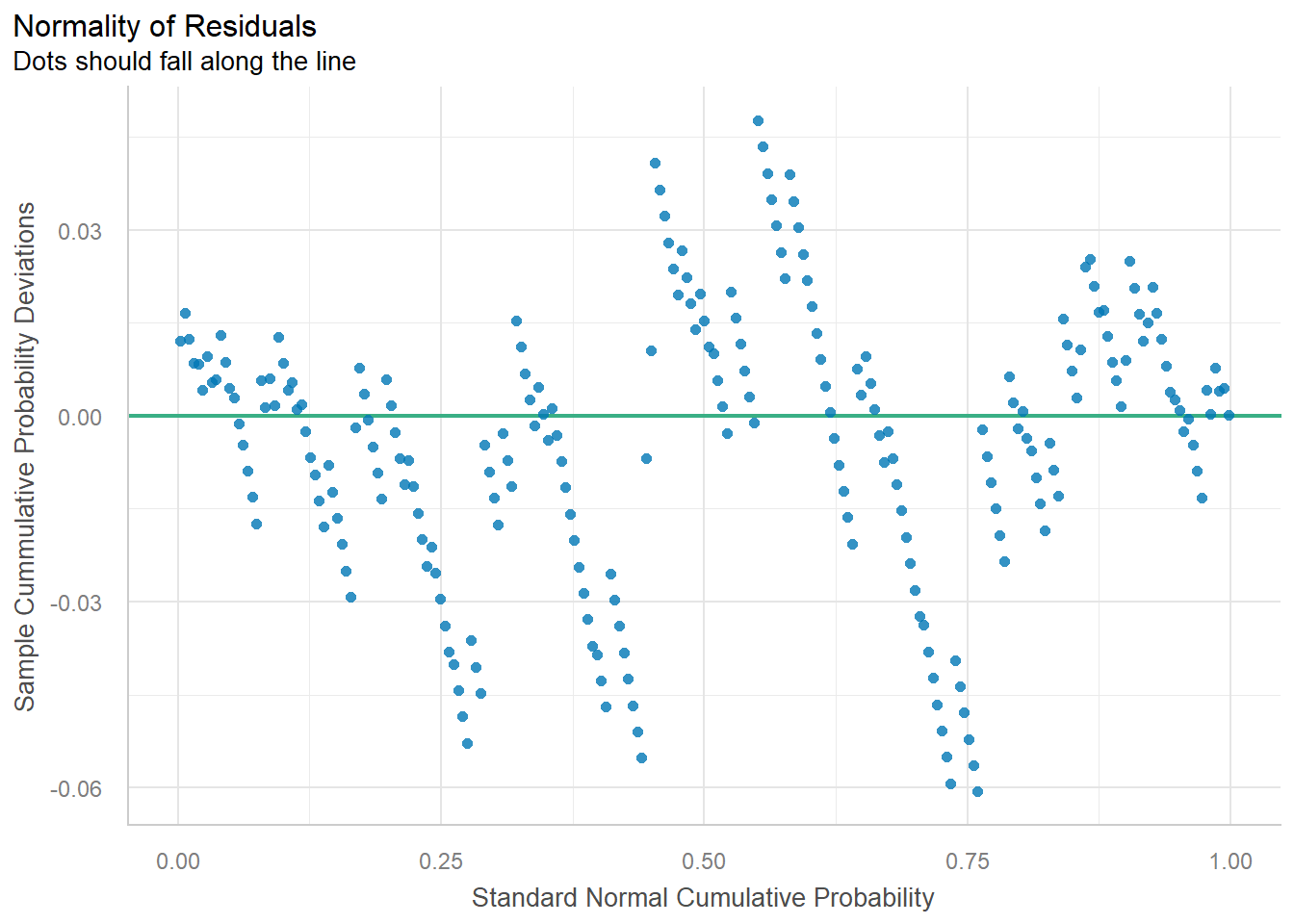
Not only do the lines look reasonably straight, the scales look similar for all eight voice parts. This similarity suggests a model where all of the errors are normal with the same standard deviation. This is convenient because it is the form of a standard linear model:
Singer height = Average height for their voice part + Normal(\(0, \sigma^2\)) error.
70.2.4 Normality of pooled residuals
If this assumption for our linear model holds, then all the residuals come from the same normal distribution.
We’ve already checked for normality of the residuals within each voice part, but to get a little more power to see divergence from normality, we can pool the residuals and make a normal QQ plot of all the residuals together. This is a little more sensitive to non-normality than the separate QQ plots.
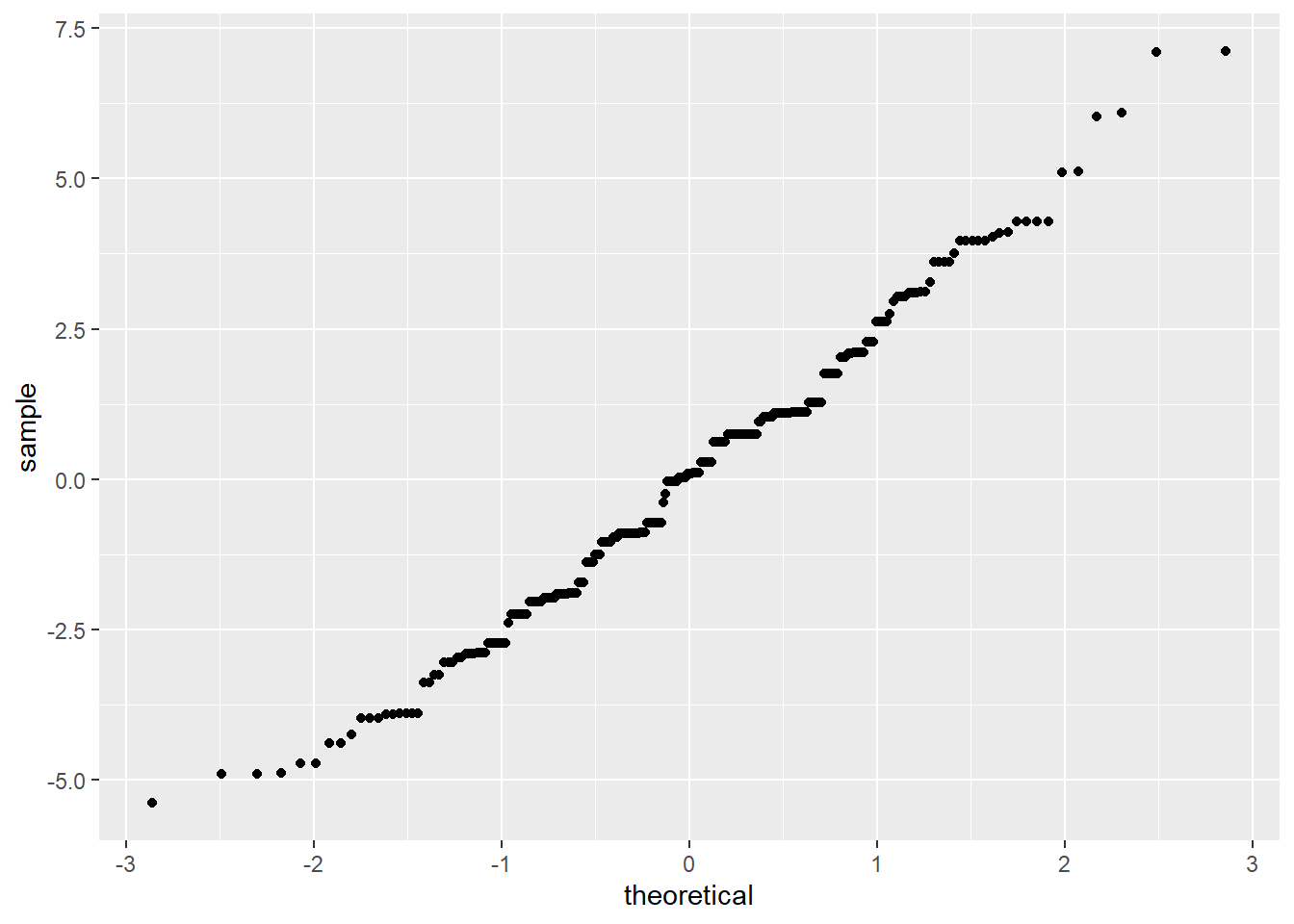
It’s easier to check normality if we plot the line that the points should fall on: if we think the points come from a \(N(\mu, \sigma^2)\) distribution, they should lie on a line with intercept \(\mu\) and slope \(\sigma\) (the standard deviation).
In the linear model, we assume that the mean of the error terms is zero. We don’t know what their variance should be, but we can estimate it using the variance of the residuals.
Therefore, we add a line with the mean of the residuals (which should be zero) as the intercept, and the SD of the residuals as the slope. This is:
ggplot(res_singer, aes(sample = residual)) +
stat_qq() +
geom_abline(aes(
intercept = 0,
slope = sd(res_singer$residual)
))
#> Warning: Use of `res_singer$residual` is discouraged.
#> ℹ Use `residual` instead.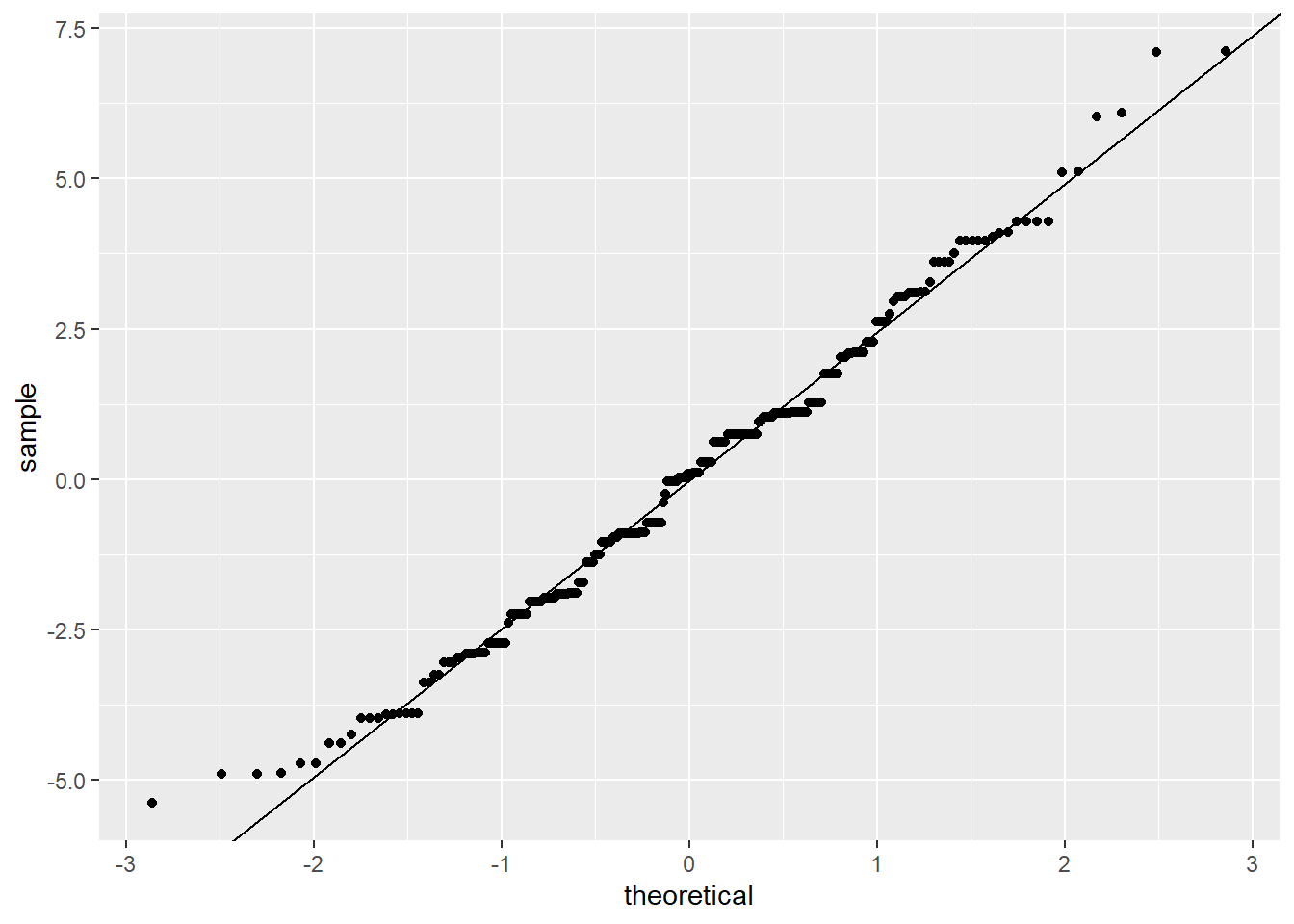
70.2.5 The actually correct way
Pedantic note: We should use an \(n-8\) denominator instead of \(n-1\) in the SD calculation for degrees of freedom reasons. The \(n-8\) part is necessary because there are 7 different variables associated with the model we fitted with lm_singer. We can get the SD directly from the linear model:
However, the difference between this adjustment and the SD above is negligible.
Add the line:
ggplot(res_singer, aes(sample = residual)) +
stat_qq() +
geom_abline(intercept = mean(res_singer$residual), slope = summary(lm_singer)$sigma)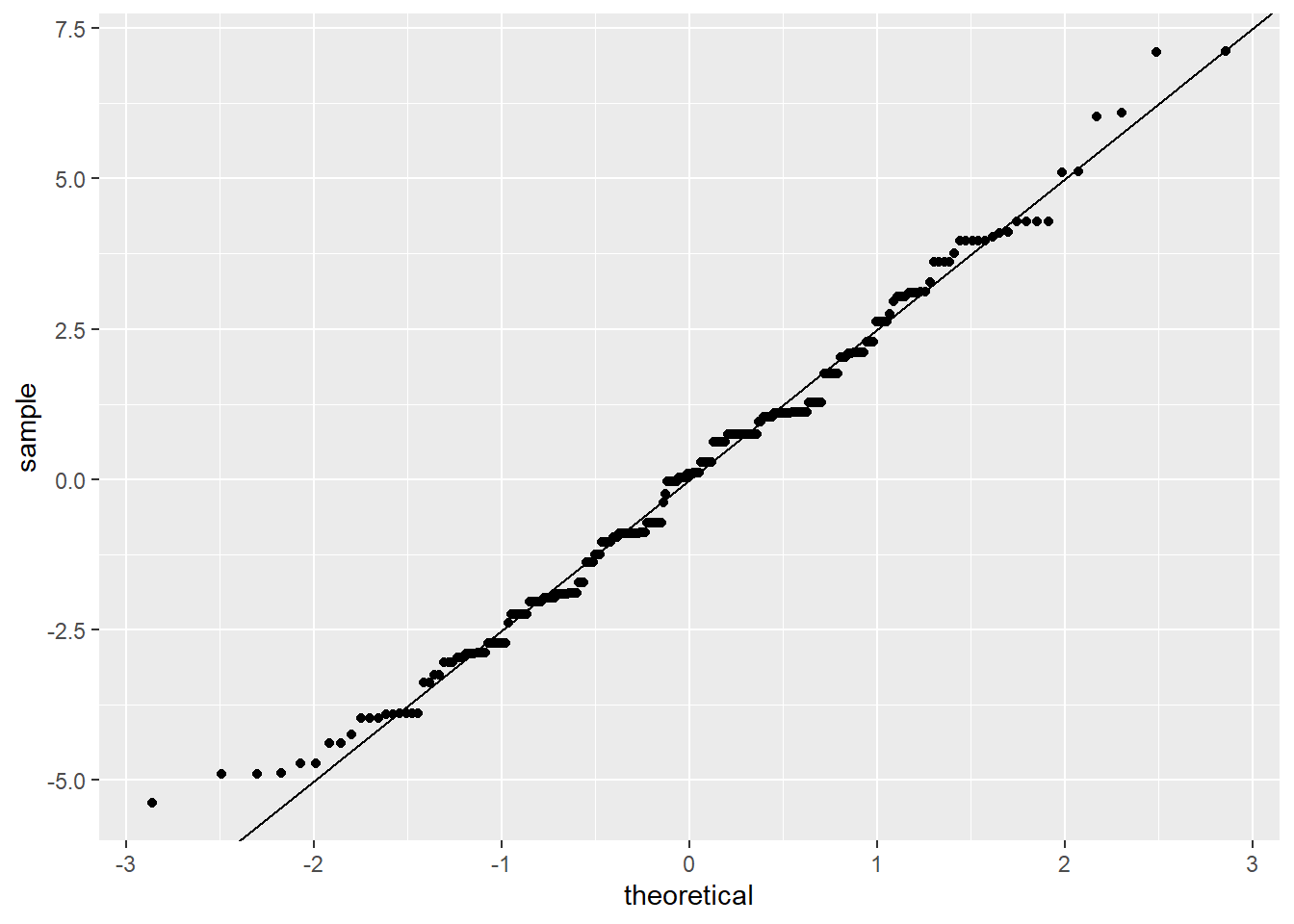
The straight line isn’t absolutely perfect, but it’s doing a pretty good job. The residuals look like they come from a normal distribution with the same variance for each voice part.
70.2.6 Our final model
Since the errors seem to be pretty normal, our final model is:
Singer height = Average height for their voice part + Normal(\(0, 2.5^2\)) error.
Note: Although normality (or lack thereof) can be important for probabilistic prediction or (sometimes) for inferential data analysis, it’s relatively unimportant for EDA. If your residuals are about normal that’s nice, but as long as they’re not horribly skewed they’re probably not a problem.
70.2.7 What have we learned?
About singers:
We’ve seen that average height increases as the voice part range decreases.
Within each voice part, the residuals look like they come from a normal distribution with the same variance for each voice part. This suggests that there’s nothing further we need to do to explain singer heights: we have an average for each voice part, and there is no suggestion of systematic differences beyond that due to voice part.
About data analysis:
We can use some of our univariate visualization tools, particularly boxplots and ecdfs, to look for evidence of heteroscedasticity.
We can use normal QQ plots on both pooled and un-pooled residuals to look for evidence of non-normality.
If we wanted to do formal tests or parameter estimation for singer heights, we would feel pretty secure using results based on normal theory.
70.2.8 Commentary on Model Performance
Somebody’s got some zero inflated count data he’s modeling as normal …
— Brenton Wiernik 🏳️🌈 (@bmwiernik) April 20, 2022
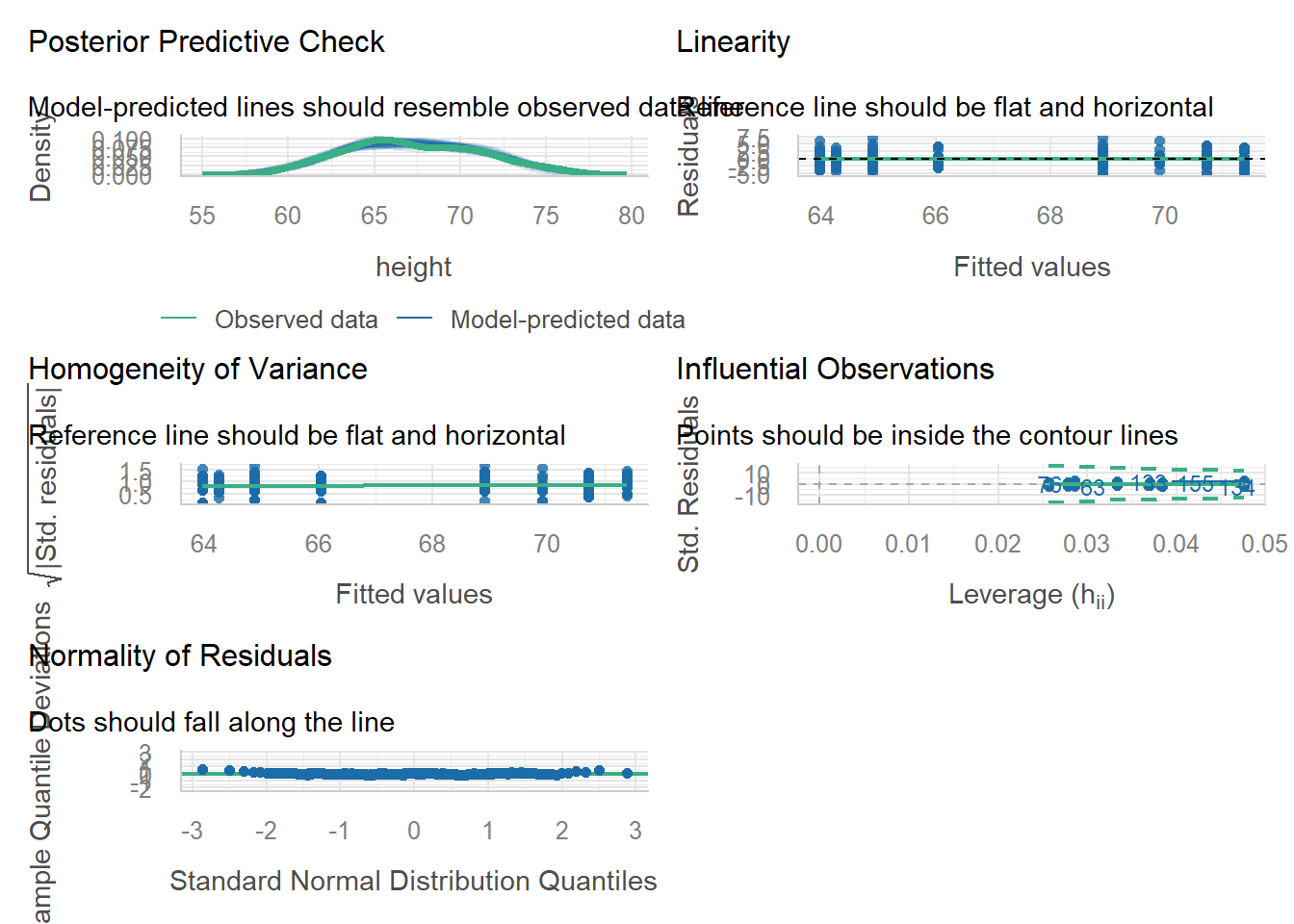
# model_performance(lm_singer)
# QQ-plot
plot(check_normality(lm_singer), type = "qq")
#> For confidence bands, please install `qqplotr`.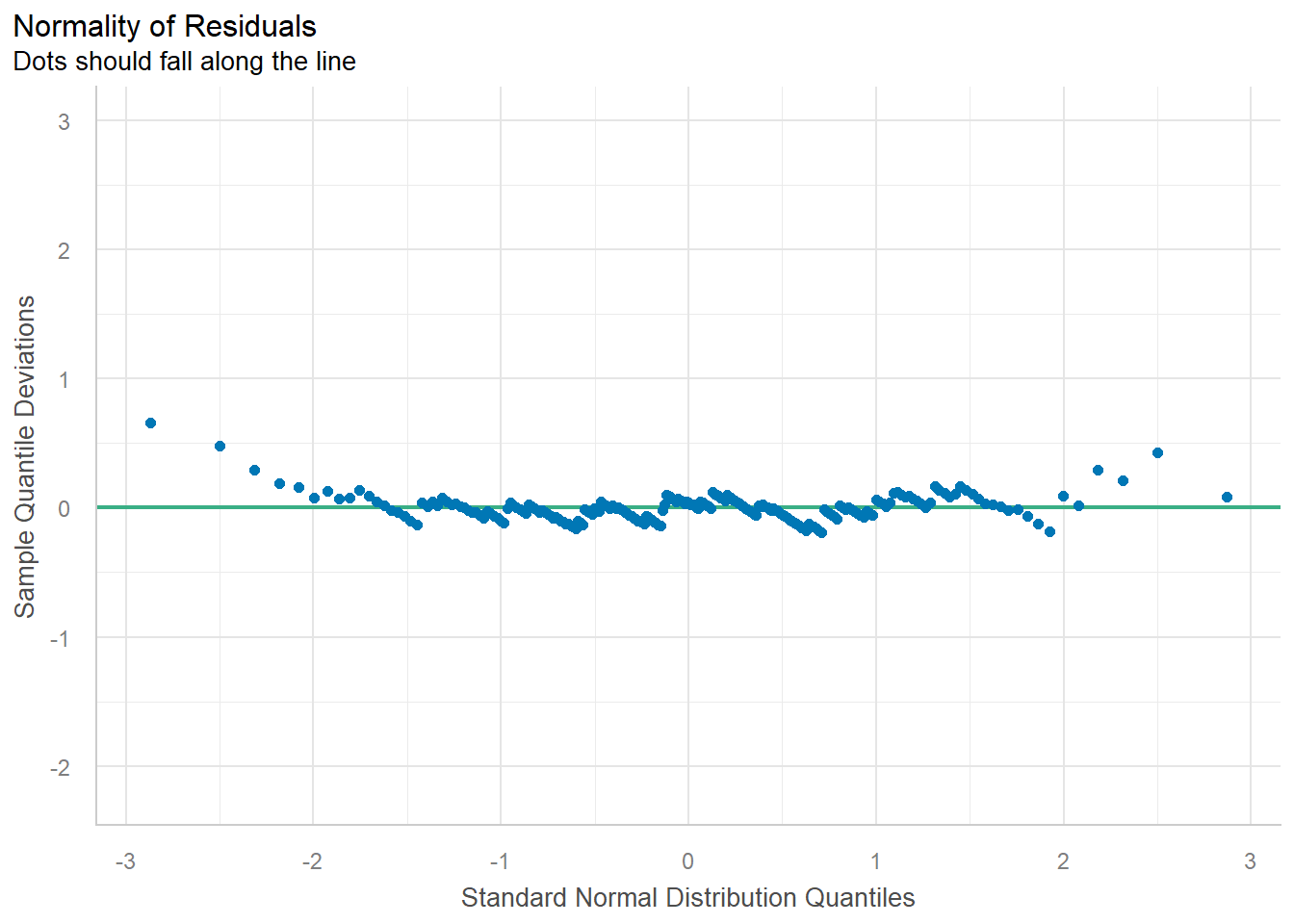
# PP-plot
plot(check_normality(lm_singer), type = "pp")
#> For confidence bands, please install `qqplotr`.