69 LAB: University of Edinburgh Art Collection
The University of Edinburgh Fine Art Collection and the Edinburgh College of Art Collection “supports the world-leading research and teaching that happens within the University. Comprised of an astonishing range of objects and ideas spanning two millennia and a multitude of artistic forms, the collection reflects not only the long and rich trajectory of the University, but also major national and international shifts in art history.”3.
Note: The joint collection contains 3311 pieces. You can explore them in the sidebar here.
In this lab, you’ll scrape data on all art pieces in the Edinburgh College of Art collection.
Learning Goals
By the end of this lab, you will:
- Scrape data from a webpage
- Write functions to automate repetitive tasks
- Use iteration to handle multiple pages
- Save and analyze scraped data
Getting started
Before we begin, let’s check whether bots are allowed to access pages on this domain.
library(robotstxt)
paths_allowed("https://collections.ed.ac.uk/art)")
#>
collections.ed.ac.uk
#> [1] TRUEGo to the course GitHub organization and locate your lab repo, which should be named something to the effect of lab-08-uoe-art. Clone the repository and set up your workspace.
R scripts vs. R Markdown documents
This lab uses both R scripts and R Markdown documents:
.R: R scripts are plain text files containing only code and brief comments,- We’ll use R scripts in the web scraping stage and ultimately save the scraped data as a csv.
.Rmd: R Markdown documents are plain text files containing.- We’ll use an R Markdown document in the web analysis stage, where we start off by reading in the csv file we wrote out in the scraping stage.
Here is the organization of your repo, and the corresponding section in the lab that each file will be used for:
|-data
| |- README.md
|-lab-08-uoe-art.Rmd # analysis
|-lab-08-uoe-art.Rproj # project management
|-README.md
|-scripts # webscraping
| |- 01-scrape-page-one.R # scraping a single page
| |- 02-scrape-page-function.R # functions
| |- 03-scrape-page-many.R # iterationSelectorGadget
For this lab, I recommend using Google Chrome as your web browser. In case you haven’t installed the SelectorGadget extension… go to the SelectorGadget extension page on the Chrome Web Store and click on “Add to Chrome” (big blue button). A pop up window will ask Add “SelectorGadget”?, click “Add extension”.
Another pop up window will ask whether you want to get your extensions on all your computer. If you want this, you can turn on sync, but you don’t need to for the purpose of this lab.

You should now be able to access SelectorGadget by clicking on the icon next to the search bar in the Chrome browser.
Scraping a single page
Tip: To run the code you can highlight or put your cursor next to the lines of code you want to run and hit Command+Enter.
Work in scripts/01-scrape-page-one.R.
We will start off by scraping data on the first 10 pieces in the collection from here.
First, we define a new object called first_url, which is the link above. Then, we read the page at this url with the read_html() function from the rvest package. The code for this is already provided in 01-scrape-page-one.R.
# set url
first_url <- "https://collections.ed.ac.uk/art/search/*:*/Collection:%22edinburgh+college+of+art%7C%7C%7CEdinburgh+College+of+Art%22?offset=0"
# read html page
page <- read_html(first_url)For the ten pieces on this page, we will extract title, artist, and link information, and put these three variables in a data frame.
Titles
Let’s start with titles. We make use of the SelectorGadget to identify the tags for the relevant nodes:
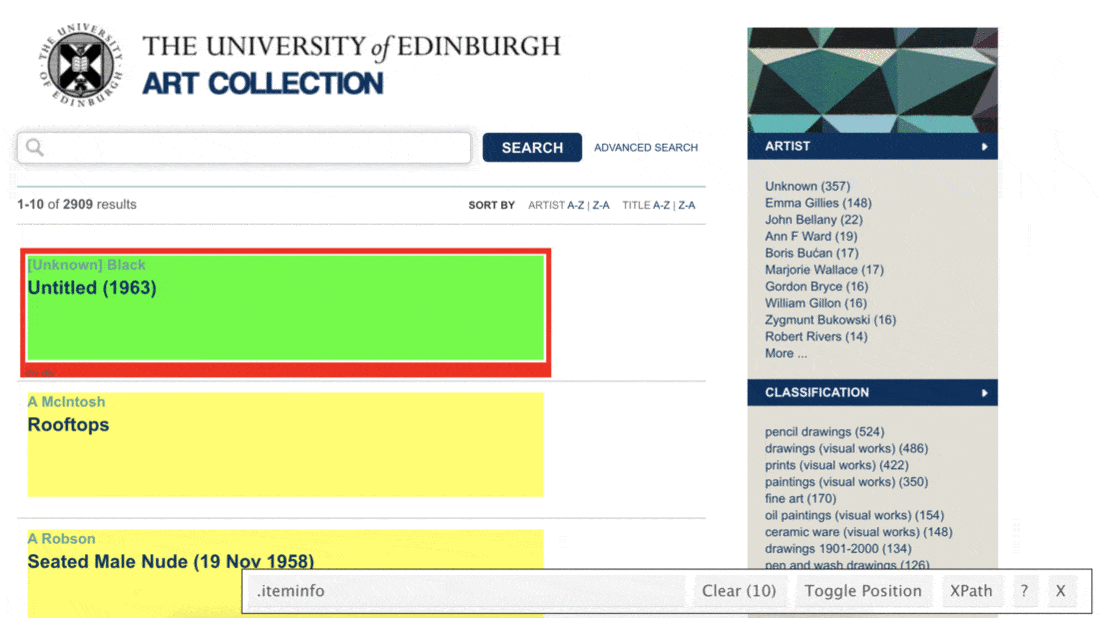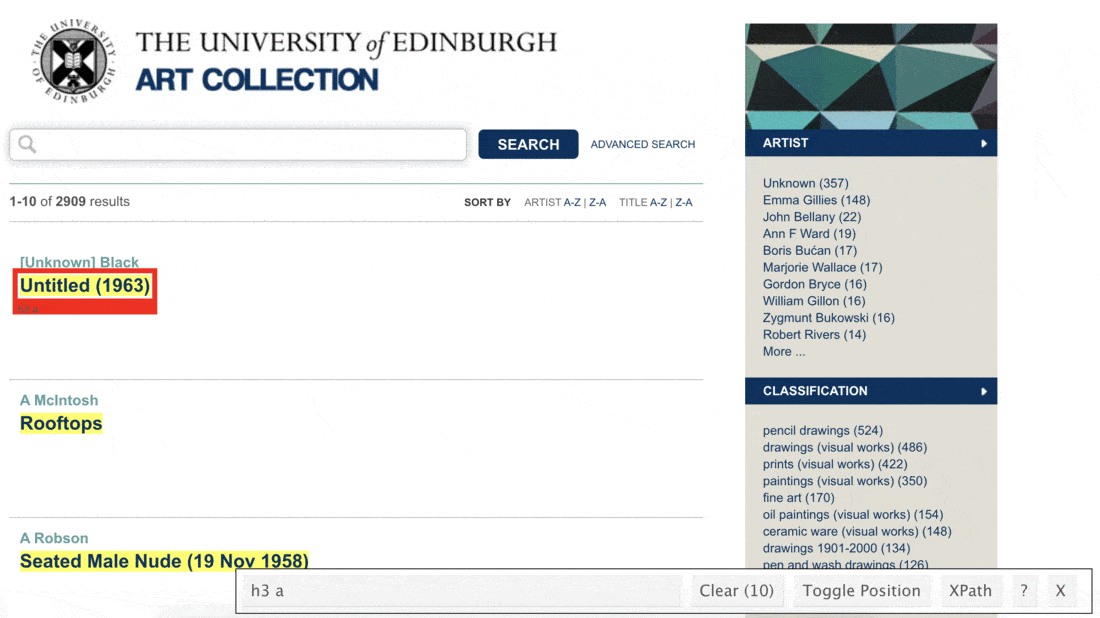
page %>%
html_nodes(".iteminfo") %>%
html_node("h3 a")
#> {xml_nodeset (10)}
#> [1] <a href="https://collections.ed.ac.uk/art/record/122849?highlight=%2A%3A ...
#> [2] <a href="https://collections.ed.ac.uk/art/record/21380?highlight=%2A%3A% ...
#> [3] <a href="https://collections.ed.ac.uk/art/record/22523?highlight=%2A%3A% ...
#> [4] <a href="https://collections.ed.ac.uk/art/record/99823?highlight=%2A%3A% ...
#> [5] <a href="https://collections.ed.ac.uk/art/record/99820?highlight=%2A%3A% ...
#> [6] <a href="https://collections.ed.ac.uk/art/record/21391?highlight=%2A%3A% ...
#> [7] <a href="https://collections.ed.ac.uk/art/record/53476?highlight=%2A%3A% ...
#> [8] <a href="https://collections.ed.ac.uk/art/record/50411?highlight=%2A%3A% ...
#> [9] <a href="https://collections.ed.ac.uk/art/record/99426?highlight=%2A%3A% ...
#> [10] <a href="https://collections.ed.ac.uk/art/record/20619?highlight=%2A%3A% ...Then we extract the text with html_text():
page %>%
html_nodes(".iteminfo") %>%
html_node("h3 a") %>%
html_text()
#> [1] "Still Life and Boat at Sea (1961)"
#> [2] "Woman Seated (1954)"
#> [3] "Border Wayleave (1990)"
#> [4] "Untitled (1980)"
#> [5] "Untitled (1967)"
#> [6] "Portrait of a Man (Circa 1951)"
#> [7] "Unknown (1950)"
#> [8] "Unknown"
#> [9] "Untitled - Woman in Hat with Ribbon (1980)"
#> [10] "Gem cabinet 5 (of 6) containing 43 medallions (Unknown)"And get rid of all the spurious whitespace in the text with str_squish():
If you’d like a hint
Take a look at the help docs forstr_squish() (with ?str_squish)
page %>%
html_nodes(".iteminfo") %>%
html_node("h3 a") %>%
html_text() %>%
str_squish()
#> [1] "Still Life and Boat at Sea (1961)"
#> [2] "Woman Seated (1954)"
#> [3] "Border Wayleave (1990)"
#> [4] "Untitled (1980)"
#> [5] "Untitled (1967)"
#> [6] "Portrait of a Man (Circa 1951)"
#> [7] "Unknown (1950)"
#> [8] "Unknown"
#> [9] "Untitled - Woman in Hat with Ribbon (1980)"
#> [10] "Gem cabinet 5 (of 6) containing 43 medallions (Unknown)"And finally save the resulting data as a vector of length 10:
Links
Now that we’ve extracted the titles, let’s collect the links to the individual art pieces. The same nodes that contain the text for the titles also contain information on the links to individual art piece pages for each title. We can extract this information using a function from the rvest package, html_attr(), which extracts attributes.
To do this, we need to understand where the links are stored on the webpage and how we can extract them.
Just like titles, links are stored inside HTML nodes. However, instead of being plain text, they are stored inside an attribute called href.
Consider the following example of a hyperlink in HTML:
<a href="https://www.google.com">Seach on Google</a>This code creates a clickable link that looks like this on a webpage: Seach on Google.
Breaking it down:
- The text displayed on the webpage is
Search on Google. - The href attribute contains the URL:
https://www.google.com.
When we extract links from a webpage, we do not extract the displayed text (e.g., “Search on Google”). Instead, we need to extract the href attribute, which contains the actual web address.
To do this, we use the rvest function html_attr("href"), which extracts the value of the href attribute from a given node.
The links to individual art pieces are stored inside the same .iteminfo nodes as the titles. Using the html_attr(“href”) function, we can extract them:
page %>%
html_nodes(".iteminfo") %>% # same nodes
html_node("h3 a") %>% # as before
html_attr("href") # but get href attribute instead of text
#> [1] "https://collections.ed.ac.uk/art/record/122849?highlight=%2A%3A%2A"
#> [2] "https://collections.ed.ac.uk/art/record/21380?highlight=%2A%3A%2A"
#> [3] "https://collections.ed.ac.uk/art/record/22523?highlight=%2A%3A%2A"
#> [4] "https://collections.ed.ac.uk/art/record/99823?highlight=%2A%3A%2A"
#> [5] "https://collections.ed.ac.uk/art/record/99820?highlight=%2A%3A%2A"
#> [6] "https://collections.ed.ac.uk/art/record/21391?highlight=%2A%3A%2A"
#> [7] "https://collections.ed.ac.uk/art/record/53476?highlight=%2A%3A%2A"
#> [8] "https://collections.ed.ac.uk/art/record/50411?highlight=%2A%3A%2A"
#> [9] "https://collections.ed.ac.uk/art/record/99426?highlight=%2A%3A%2A"
#> [10] "https://collections.ed.ac.uk/art/record/20619?highlight=%2A%3A%2A"Now, print the first few results:
head(links)You should see output similar to this:
/art/record/215578
/art/record/997987
/art/record/220175At first glance, this looks correct—the links match what we see on the webpage. However, there’s a problem: these are not full URLs. They’re relative links.
Note: See the help for
str_replace()to find out how it works. Remember that the first argument is passed in from the pipeline, so you just need to define thepatternandreplacementarguments.
- Click on one of art piece titles in your browser and take note of the URL of the webpage it takes you to. How does that URL compare to what we scraped above? How is it different? Using
str_replace(), fix the URLs.
Functions
Work in scripts/02-scrape-page-function.R.
You’ve been using R functions, now it’s time to write your own!
Let’s start simple. Here is a function that takes in an argument x, and adds 2 to it.
Let’s test it:
The skeleton for defining functions in R is as follows:
Then, a function for scraping a page should look something like:
Tip: Function names should be short but evocative verbs.
function_name <- function(url) {
# read page at url
# extract title, link, artist info for n pieces on page
# return a n x 3 tibble
}Fill in the blanks using code you already developed in the previous exercises. Name the function
scrape_page.Test out your new function by running the following in the console. Does the output look right?
Iteration
Work in scripts/03-scrape-page-many.R.
We went from manually scraping individual pages to writing a function to do the same. Next, we will make our workflow a little more efficient by using R to iterate over all pages that contain information on the art collection.
Reminder: The collection has 3311 pieces in total, as of the last time this page was compiled.
That means we will develop a list of URLs, each corresponding to a page with 10 art pieces. Then, we will write some code that applies the scrape_page() function to each page and combines the resulting data frames into a single data frame with 3311 rows and 3 columns.
List of URLs
Click through the first few pages of the art collection and observe their URLs to confirm the following pattern:
[sometext]offset=0 # Pieces 1-10
[sometext]offset=10 # Pieces 11-20
[sometext]offset=20 # Pieces 21-30
[sometext]offset=30 # Pieces 31-40
...
[sometext]offset=3310 # Pieces 3310-3319We can construct these URLs in R by pasting together two pieces: (1) a common (root) text for the beginning of the URL, and (2) numbers starting at 0, increasing by 10, all the way up to 3310. Two useful functions for accomplishing this task are paste0() for pasting two pieces of text and seq() for generating a sequence of numbers.
- Fill in the blanks to construct the list of URLs.
Mapping
Finally, we are ready to iterate over the list of URLs we constructed. We will do this by mapping the function we developed over the list of URLs. Mapping functions in R apply a function to each element of a list. These functions each take the following form:
map([x], [function to apply to each element of x])In our case:
xis the list of URLs we just constructed- The function to apply is
scrape_page(), which we developed earlier. - Since we want a data frame, we use
map_dfr()to return a combined tibble.
- Fill in the blanks to scrape all pages and create a data frame called
uoe_art.
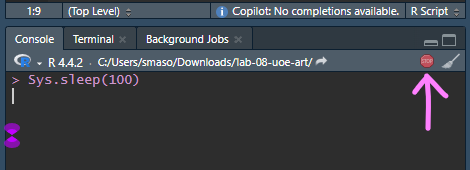
Be patient, this will take a few minutes to run. It’s literally scraping 331 pages of data. If its still running you’ll see a stop sign in the corner of the console.
Analysis
Work in lab-08-uoe-art.Rmd for the rest of the lab.
Now that you have a tidy dataset, you’ll analyze it. Follow the steps below.
69.0.1 Step 1: Cleaning Up the Titles and Dates
Some titles contain date information in parentheses. Some of these are years, others are more specific dates, some art pieces have no date information whatsoever, and others have some non-date information in parentheses.
First thing, we’ll try is to separate the title column into two: one for the actual title and the other for the date if it exists. In human speak, we need to
separate the
titlecolumn at the first occurence of(and put the contents on one side of the(into a column calledtitleand the contents on the other side into a column calleddate
Luckily, there’s a function that does just this: separate()!
Once we have completed separating the single title column into title and date, we need to do further cleanup in the date column to get rid of extraneous )s with str_remove(), capture year information, and save the data as a numeric variable.
Hint: Remember escaping special characters from that video? Which video… oh you know the one. You’ll need to use that trick again.
Fill in the blanks to implement the data wrangling we described above. Note that this approach will result in some warnings when you run the code, and that’s OK! Read the warnings, and explain what they mean, and why we are ok with leaving them in given that our objective is to just capture
yearwhere it’s convenient to do so.Print out a summary of the data frame using the
skim()function. How many pieces have artist info missing? How many have year info missing?Make a histogram of years. Use a reasonable bin width. Do you see anything out of the ordinary?
Find which piece has the out-of-the-ordinary year and go to its page on the art collection website to find the correct year for it. Can you tell why our code didn’t capture the correct year information? Correct the error in the data frame and visualize the data again.
Hint: You’ll want to use
mutate()andif_else()orcase_when()to implement the correction.
Who is the most commonly featured artist in the collection? Do you know them? Any guess as to why the university has so many pieces from them?
Final question! How many art pieces have the word “child” in their title? See if you can figure it out, and ask for help if not.
Hint: You can use a combination of
filter()andstr_detect(). You will want to read the help forstr_detect()at a minimum, and consider how you might capture titles where the word appears as “child” and “Child”.