86 ODD: Notes on Cross validation
These lecture notes are an optional deep-dive into cross-validation. The lecture presents examples from regression and mixture models. I highlight the effectiveness of resampling methods like cross-validation when the observed data accurately reflects the true data-generating distribution.
We have:
Data \(X_1, \ldots, X_n\).
A tuning parameter \(\theta\). Each value of \(\theta\) corresponds to a different set of models.
A function \(L\) that takes a fitted model and a data point and returns a measure of model quality.
We would like to choose one model from the set of candidate models indexed by \(\theta\).
86.1 Example: Regression
Data: Pairs of predictors and response variables, \((y_i, X_i)\), \(i = 1,\ldots, n\), \(y_i \in \mathbb R\), \(X_i \in \mathbb R^p\)
Models: \(y_i = X \beta + \epsilon\), \(\beta_j = 0, j \in S_\theta\), where \(S_\theta \subseteq \{1,\ldots, p\}\).
Model quality: Squared-error loss. If \(\hat \beta_\theta\) are our estimates of the regression coefficients in model \(\theta\), model quality is measured by
\[ L(\hat \beta_\theta, (y_i, X_i)) = (y_i - X_i^T \hat \beta_\theta)^2 \]
We want to choose a subset of the predictors that do the best job of explaining the response.
Naive solution: Find the model that has the lowest value for the squared-error loss.
Why doesn’t this work?
86.2 Example: Mixture models
Data: \(x_1,\ldots, x_n\), \(x_i \in \mathbb R\)
Models: Gaussian mixture models with \(\theta\) mixture components.
Model quality: Negative log likelihood of the data. If \(\hat p_\theta\) is the density of the fitted model with \(\theta\) components, model quality is measured by \(L(\hat p_\theta, x_i) = -\log \hat p_\theta(x_i)\).
We want to choose the number of mixture components that best explains the data.
Naive solution: Choose the number of mixture components that minimizes the negative log likelihood of the data.
86.3 Better Solution: Cross validation
Idea: Instead of measuring model quality on the same data we used to fit the model, we estimate model quality on new data.
If we knew the true distribution of the data, we could simulate new data and use a Monte Carlo estimate based on the simulations.
We can’t actually get new data, and so we hold some back when we fit the model and then pretend that the held back data is new data.
Procedure:
Divide the data into \(K\) folds
Let \(X^{(k)}\) denote the data in fold \(k\), and let \(X^{(-k)}\) denote the data in all the folds except for \(k\).
For each fold and each value of the tuning parameter \(\theta\), fit the model on \(X^{(-k)}\) to get \(\hat f_\theta^{(k)}\)
Compute
\[ \text{CV}(\theta) = \frac{1}{n} \sum_{k=1}^K \sum_{x \in X^{(k)}} L(\hat f_\theta^{(k)}, x) \]
- Choose \(\hat \theta = \text{argmin}_{\theta} \text{CV}(\theta)\)
86.4 Example
n <- 100
p <- 20
X <- matrix(rnorm(n * p), nrow = n)
y <- rnorm(n)
get_rss_submodels <- function(n_predictors, y, X) {
if (n_predictors == 0) {
lm_submodel <- lm(y ~ 0)
} else {
lm_submodel <- lm(y ~ 0 + X[, 1:n_predictors, drop = FALSE])
}
return(sum(residuals(lm_submodel)^2))
}
p_vec <- 0:p
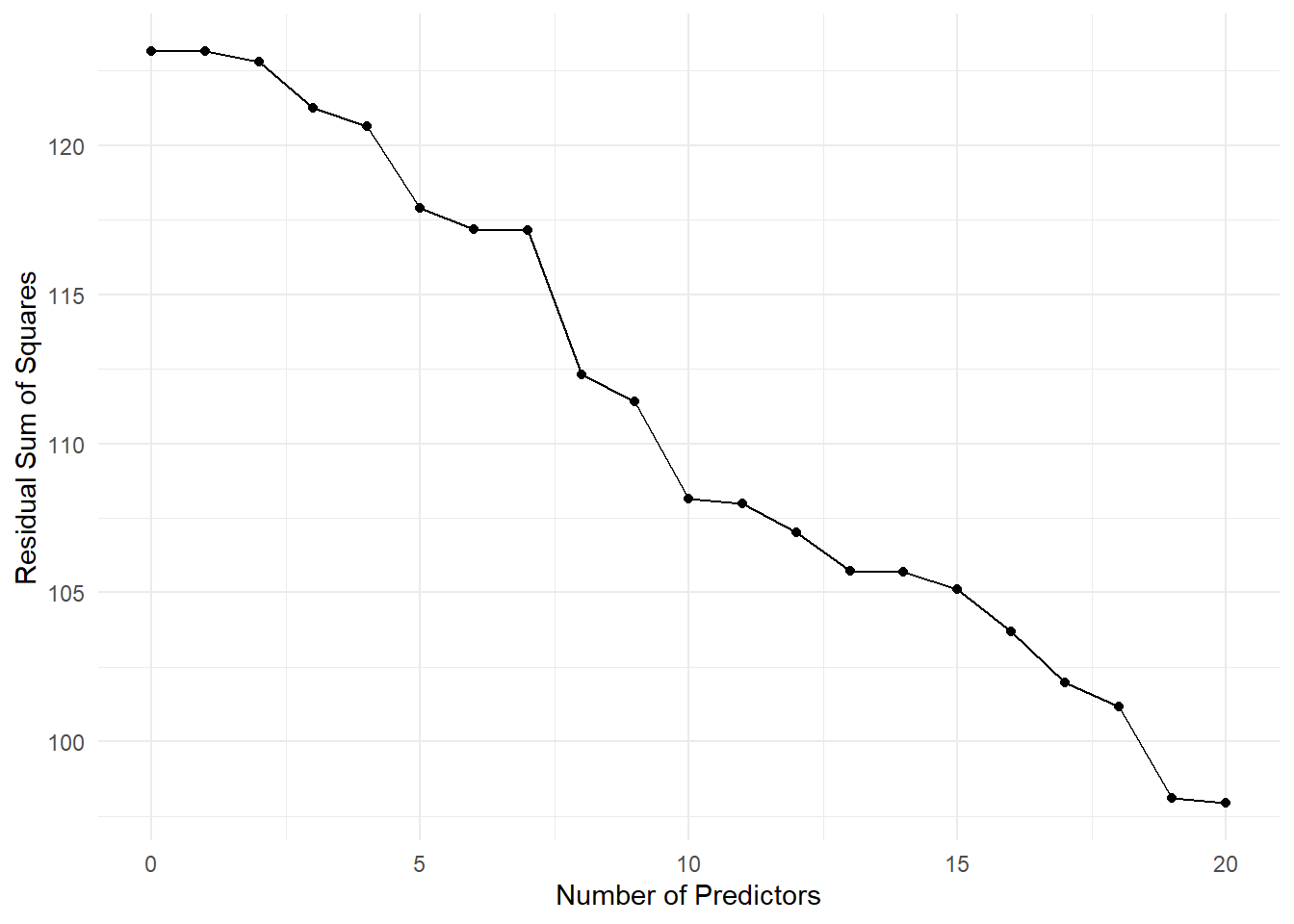
rss <- sapply(p_vec, get_rss_submodels, y, X)Here is a plot of the residual sum of squares as a function of the number of predictors in the model. As we add more predictors, the residual sum of squares decreases. However, after a certain point, adding more predictors does not substantially improve the model fit. Cross-validation can help us identify the optimal number of predictors to include in the model.
86.4.1 Cross-validation to estimate prediction error
The function below computes the cross-validated estimate of prediction error for a given number of predictors.
get_cv_error <- function(n_predictors,
y,
X,
folds) {
cv_vec <- numeric(length(unique(folds)))
for (f in unique(folds)) {
cv_vec[f] <- rss_on_held_out(
n_predictors,
y_train = y[folds != f],
X_train = X[folds != f, ],
y_test = y[folds == f],
X_test = X[folds == f, ]
)
}
return(mean(cv_vec))
}This function computes the residual sum of squares on held-out data for a given number of predictors.
rss_on_held_out <- function(n_predictors,
y_train,
X_train,
y_test,
X_test) {
if (n_predictors == 0) {
lm_submodel <- lm(y_train ~ 0)
preds_on_test <- rep(0, length(y_test))
} else {
lm_submodel <- lm(y_train ~ 0 + X_train[, 1:n_predictors, drop = FALSE])
preds_on_test <- X_test[, 1:n_predictors, drop = FALSE] %*% coef(lm_submodel)
}
return(sum((y_test - preds_on_test)^2))
}
K <- 5
## normally you would do this at random
folds <- rep(1:K, each = n / K)
p_vec <- 0:p
cv_errors <- sapply(p_vec, get_cv_error, y, X, folds)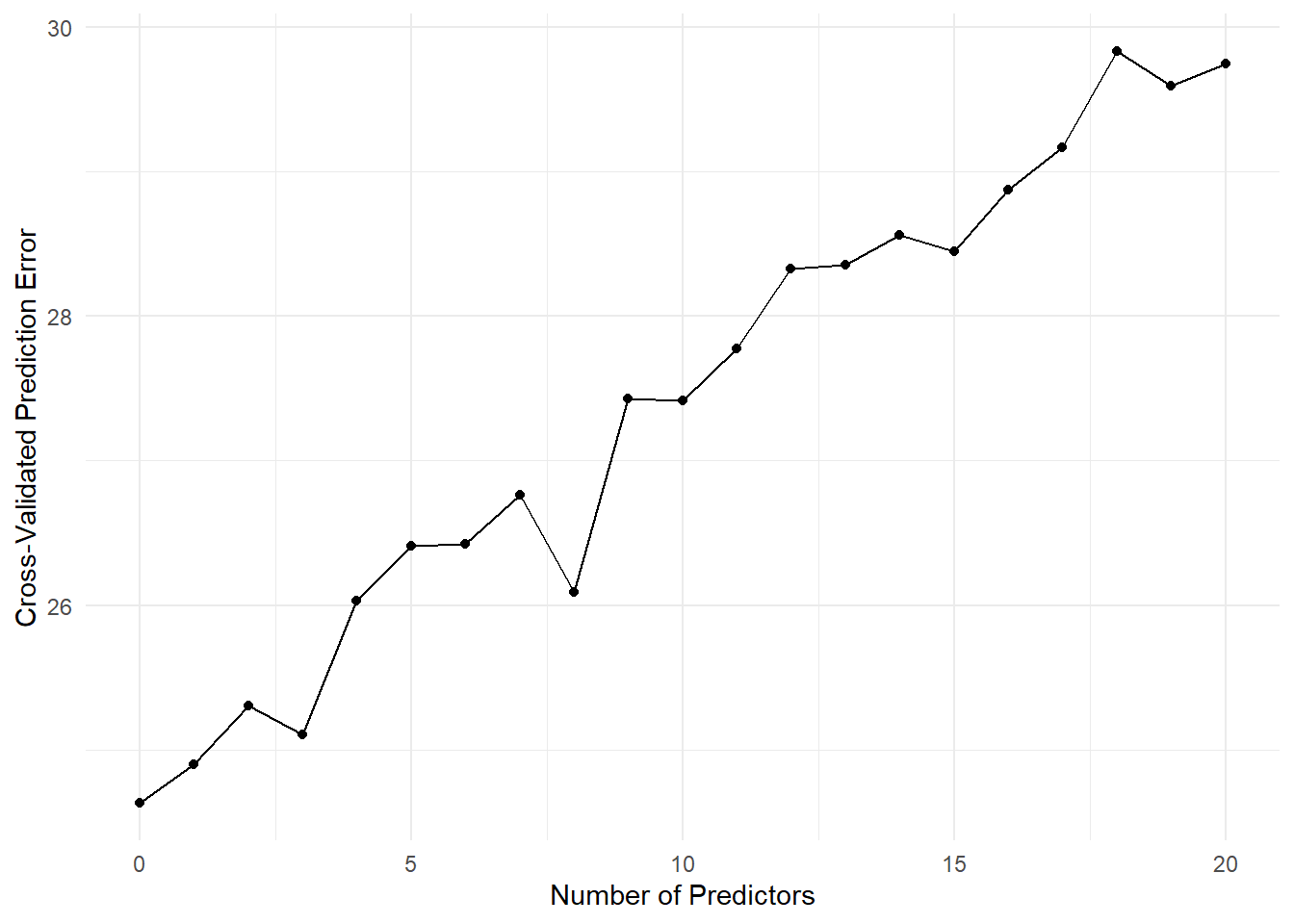
As we can see from the plot, the cross-validated prediction error initially decreases as we add more predictors to the model. However, after a certain point, adding more predictors leads to an increase in prediction error, indicating overfitting. The optimal number of predictors is the one that minimizes the cross-validated prediction error.
86.5 Choice of \(K\)
Considerations:
Larger \(K\) means more computation (although sometimes there is a shortcut for leave-one-out cross validation)
Larger \(K\) means less bias in the estimate of model accuracy
Larger \(K\) also means more variance in the estimate, so we don’t necessarily want \(K = n\)
Usually choose \(K = 5\) or \(K = 10\)
If your problem is structured (e.g. time series, spatial), you should choose the folds to respect the structure.
86.6 Summing up
We can use simulations to estimate arbitrary functions of our random variables.
If we know the underlying distribution, we can simply simulate from it (Monte Carlo integration).
If we don’t know the underlying distribution, we can “simulate” from the data by resampling from the data (cross validation; ish). Resampling methods will do well to the extent that the observed data reflect the true data-generating distribution.