48 ODD: Secrets of a happy graphing life
This optional deep dive (ODD) explores some key principles for effective data visualization in R. While it may seem like graphs are just the final step of analysis, many graphing headaches actually stem from data wrangling issues earlier in the process. Let’s look at some tips to make your visualization workflow smoother.
48.2 Data Frames are Your Friends
A common rookie mistake is pulling variables out of data frames to work with them separately:
While this might seem convenient, it causes headaches down the road. Instead, keep your variables together in a data frame and pass the whole thing to ggplot2:
Just leave the variables in place and pass the associated data frame! This advice applies to base and lattice graphics as well. It is not specific to ggplot2.
What if we wanted to filter the data by country, continent, or year? This is much easier to do safely if all affected variables live together in a data frame, not as individual objects that can get “out of sync.”
Don’t write-off ggplot2 as a highly opinionated outlier! In fact, keeping data in data frames and computing and visualizing it in situ are widely regarded as best practices. The option to pass a data frame via data = is a common feature of many high-use R functions, e.g. lm(), aggregate(), plot(), and t.test(), so make this your default modus operandi.
48.2.1 Explicit data frame creation via tibble::tibble() and tibble::tribble()
If your data is already lying around and it’s not in a data frame, ask yourself “why not?”. Did you create those variables? Maybe you should have created them in a data frame in the first place! The tibble() function is an improved version of the built-in data.frame(), which makes it possible to define one variable in terms of another and which won’t turn character data into factor. If constructing tiny tibbles “by hand”, tribble() can be an even handier function, in which your code will be laid out like the table you are creating. These functions should remove the most common excuses for data frame procrastination and avoidance.
my_dat <-
tibble(
x = 1:5,
y = x^2,
text = c("alpha", "beta", "gamma", "delta", "epsilon")
)
## if you're truly "hand coding", tribble() is an alternative
my_dat <- tribble(
~x, ~y, ~text,
1, 1, "alpha",
2, 4, "beta",
3, 9, "gamma",
4, 16, "delta",
5, 25, "epsilon"
)
str(my_dat)
#> tibble [5 × 3] (S3: tbl_df/tbl/data.frame)
#> $ x : num [1:5] 1 2 3 4 5
#> $ y : num [1:5] 1 4 9 16 25
#> $ text: chr [1:5] "alpha" "beta" "gamma" "delta" ...
ggplot(
my_dat,
aes(x, y)
) +
geom_line() +
geom_text(aes(label = text))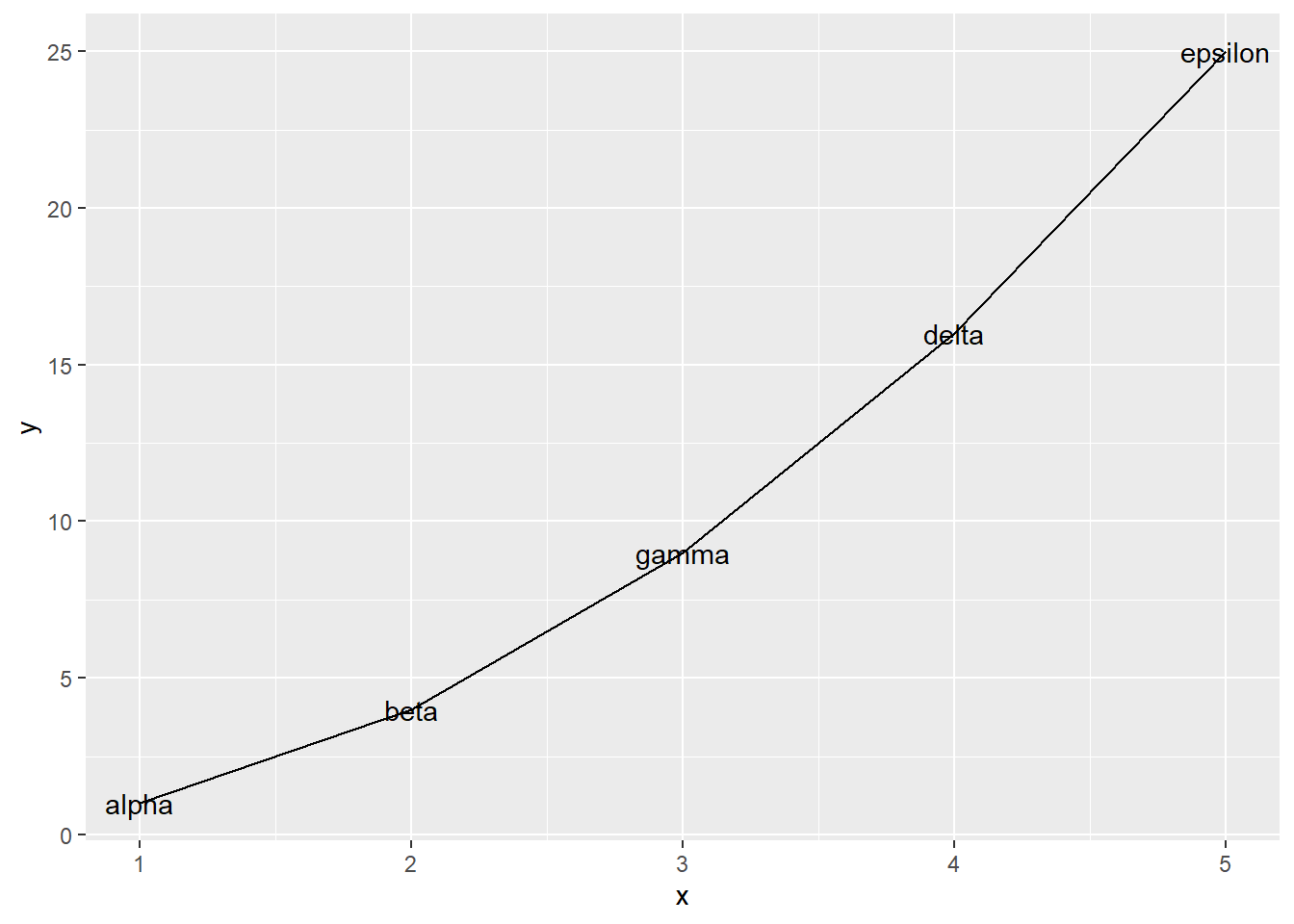
Together with dplyr::mutate(), which adds new variables to a data frame, this gives you the tools to work within data frames whenever you’re handling related variables of the same length.
48.3 Worked example
Inspired by this question from a student when we first started using ggplot2: How can I focus in on country, Japan for example, and plot all the quantitative variables against year?
Your first instinct might be to filter the Gapminder data for Japan and then loop over the variables, creating separate plots which need to be glued together. And, indeed, this can be done. But in my opinion, the data reshaping route is more “R native” given our current ecosystem, than the loop way.
48.3.1 Reshape your data
We filter the Gapminder data and keep only Japan. Then we use tidyr::gather() to gather up the variables pop, lifeExp, and gdpPercap into a single value variable, with a companion variable key.
japan_dat <- gapminder %>%
filter(country == "Japan")
japan_tidy <- japan_dat %>%
gather(
key = var,
value = value,
pop, lifeExp, gdpPercap
)
dim(japan_dat)
#> [1] 12 6
dim(japan_tidy)
#> [1] 36 5The filtered japan_dat has 12 rows. Since we are gathering or stacking three variables in japan_tidy, it makes sense to see three times as many rows, namely 36 in the reshaped result.
48.3.2 Iterate over the variables via faceting
Now that we have the data we need in a tidy data frame, with a proper factor representing the variables we want to “iterate” over, we just have to facet.
p <- ggplot(japan_tidy, aes(x = year, y = value)) +
facet_wrap(~var, scales = "free_y")
p + geom_point() + geom_line() +
scale_x_continuous(breaks = seq(1950, 2011, 15))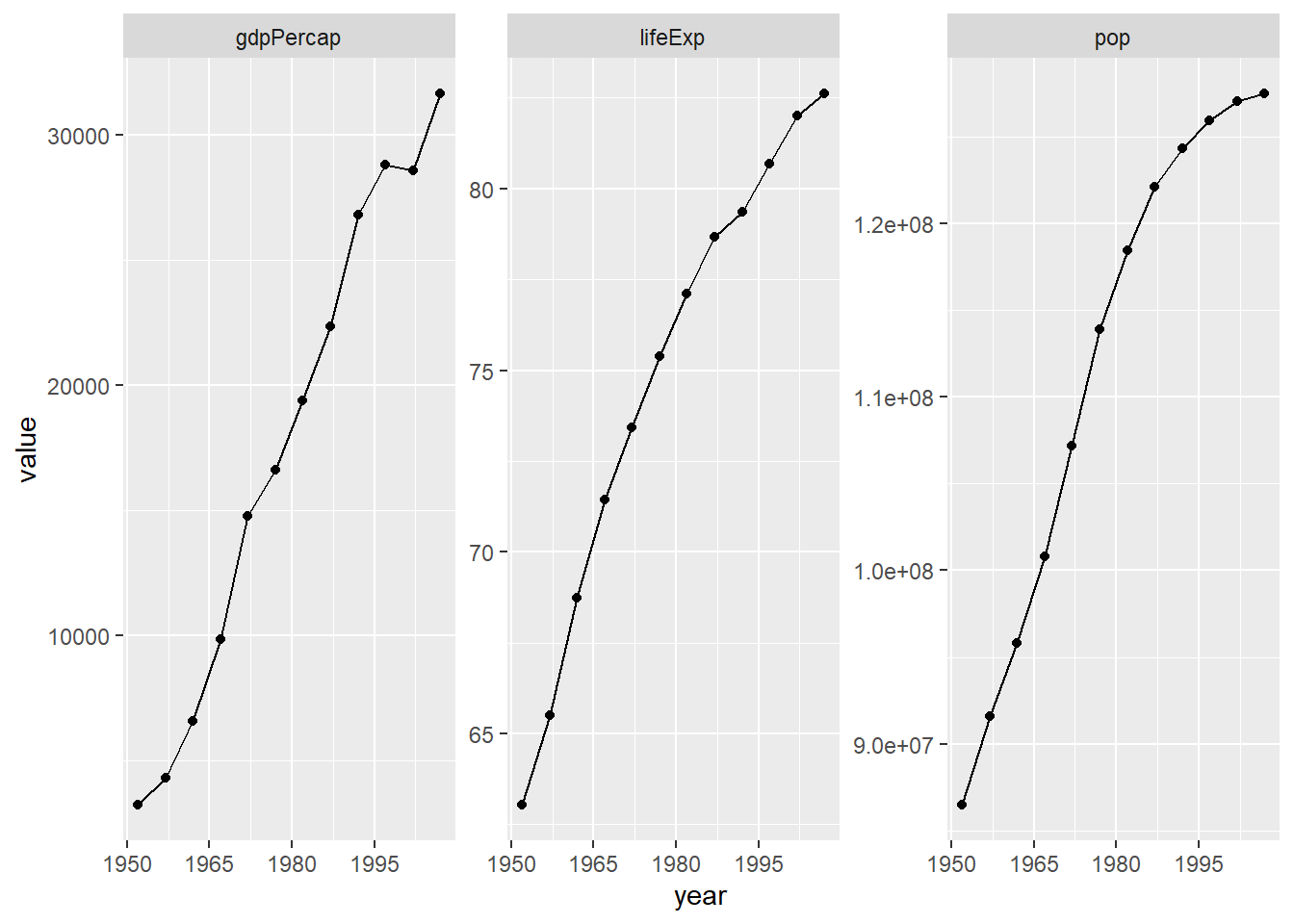
48.3.3 Recap
Here’s the minimal code to produce our Japan example.
japan_tidy <- gapminder %>%
filter(country == "Japan") %>%
gather(key = var, value = value, pop, lifeExp, gdpPercap)
ggplot(japan_tidy, aes(x = year, y = value)) +
facet_wrap(~var, scales = "free_y") +
geom_point() +
geom_line() +
scale_x_continuous(breaks = seq(1950, 2011, 15))This snippet demonstrates the payoffs from the rules we laid out at the start:
- We isolate the Japan data into its own data frame.
- We reshape the data. We gather three columns into one, because we want to depict them via position along the y-axis in the plot.
- We use a factor to distinguish the observations that belong in each mini-plot, which then becomes a simple application of faceting.
- This is an example of expedient data reshaping. I don’t actually believe that
gdpPercap,lifeExp, andpopnaturally belong together in one variable. But gathering them was by far the easiest way to get this plot.