62 LAB: Better Viz
Conveying the right message through visualization
In this lab, you’ll play data detective. You’ll start with a misleading visualization and no data, then track down the original sources on the web, wrangle raw data into shape, and use it to both reconstruct and improve the visualization. Along the way, you’ll practice the data acquisition and wrangling skills from this module.
Learning Goals
- Downloading data directly from URLs using
read_csv()(direct download from the data acquisition spectrum) - Wrangling real-world data with
pivot_longer(),filter(),mutate(),case_when(),left_join(),group_by(), andsummarize() - Working with dates using the
lubridatepackage - Computing rolling averages with
zoo::rollmean() - Using
str_remove()for string manipulation - Critiquing visualizations that misrepresent data
- Applying principles of effective data visualizations to improve clarity and accuracy
Getting started
Go to the course GitHub organization and locate the template. Clone and then open the R Markdown document. Ensure it compiles without errors to confirm your setup is correct.
Warm up
Let’s warm up with some simple exercises. Update the YAML of your R Markdown file with your information, knit, commit, and push your changes. Make sure to commit with a meaningful commit message. Then, go to your repo on GitHub and confirm that your changes are visible in your Rmd and md files. If anything is missing, commit and push again.
Packages
We’ll use the tidyverse for data wrangling and visualization, along with several packages for working with web data and dates that we’ve been learning about in this module.
Data
Unlike previous labs, you won’t be starting with a tidy, ready-to-use dataset. Instead, you’ll be acquiring and building the dataset yourself from publicly available web sources — just like a former student, Holland, did when they first tried to fact-check this visualization. The data you need is out there, but it takes some detective work to find it and some wrangling to get it into a usable form. If you’re interested in Holland’s original approach, you can refer to this repository for the full pipeline and sources.
Exercises
The following visualization was shared on Twitter as “extraordinary misleading”.
Hey, @maddow and @MaddowBlog @SecNormanas as much as we'd all hope everyone would wear masks, this chart is extraordinary misleading. If you don't believe me, ask @AlbertoCairo who wrote the book on it. Check the scale on the two axes. pic.twitter.com/JLxxgxzbua
— Jon Boeckenstedt (@JonBoeckenstedt) August 7, 2020
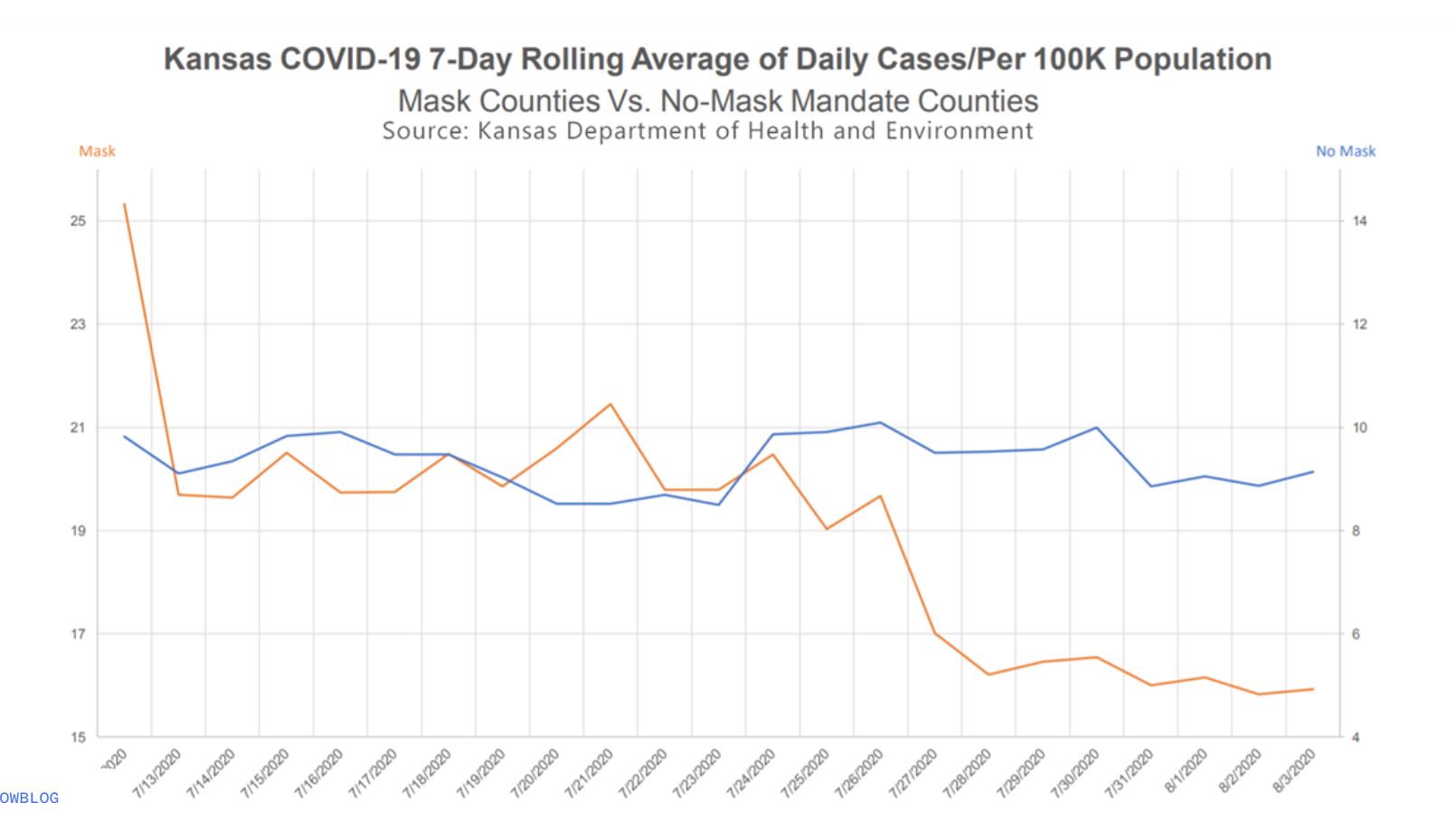
Here’s a close attempt at reconstructing the original plot. Can you spot the differences?
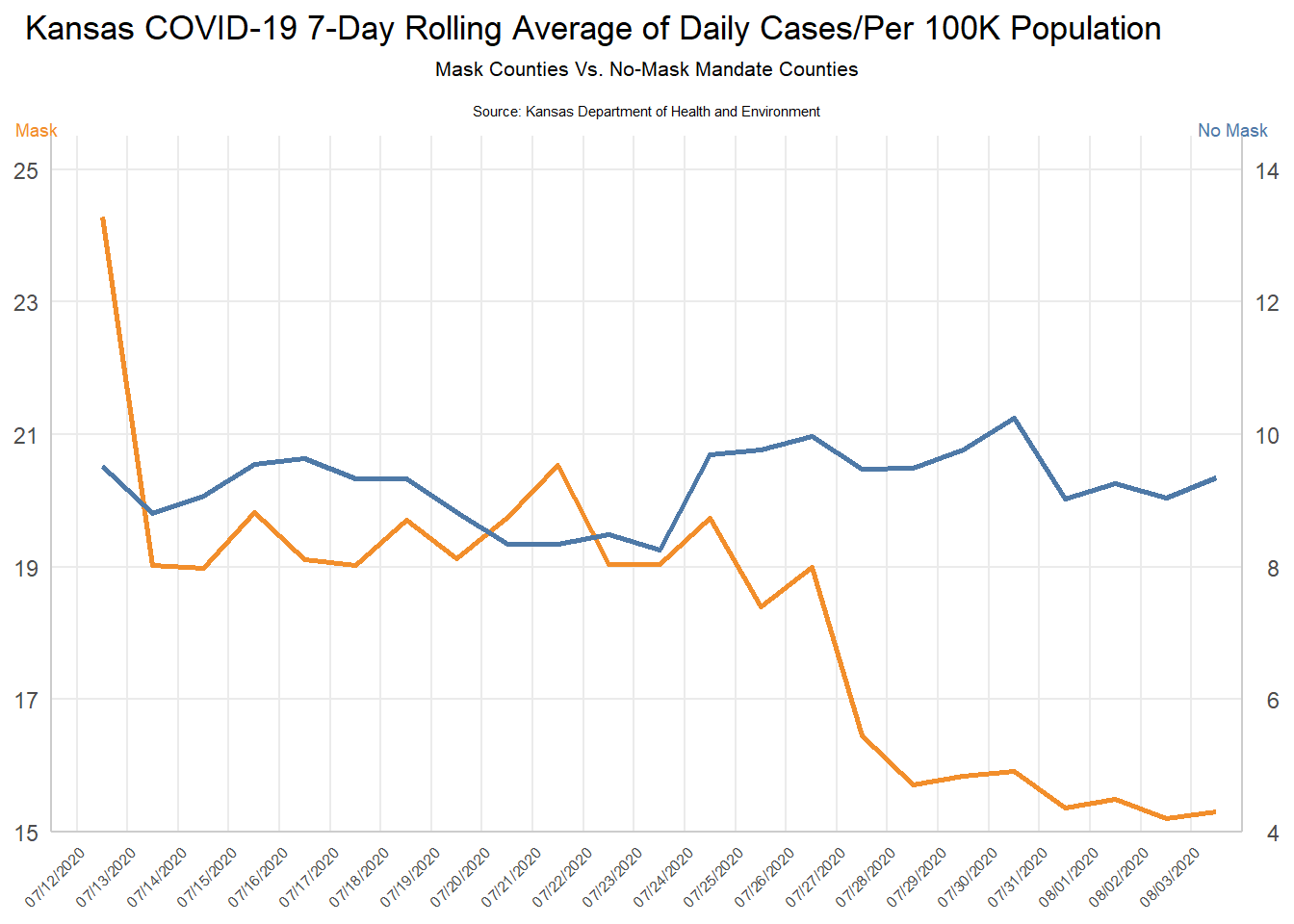
Before you dive in, think about what is misleading about this visualization and how you might go about fixing it.
Part 1: The Problem — Where’s the Data?
This visualization was presented at a KDHE press conference, but the underlying data was never released. If you wanted to fact-check it, where would you even start? A former student, Holland, faced exactly this problem and did some impressive detective work to track down the data. Let’s retrace that journey.
Look carefully at the original visualization. What information does it give you about where the data might come from? Read the title, subtitle, axis labels, and source line. Write down what you can infer about the data: What state? What time period? What’s being measured? What are the two groups being compared? What does “per 100K population” tell you about how the data was calculated?
Holland’s first breakthrough was finding a CDC MMWR report by Van Dyke et al. (2020) that analyzed this exact comparison. Skim the report (focus on the methods section). What key pieces of information does it reveal that the original visualization didn’t? In particular, look for: (a) the names of the counties that had mask mandates, and (b) any mention of where the case data came from.
Part 2: Acquiring the Raw Data
The MMWR report tells us the case data came from USAFacts, which provides county-level COVID-19 data as downloadable CSV files. This is a direct download — the simplest method on the data acquisition spectrum we discussed in this module. No API key needed, no scraping required — just a URL and read_csv().
- Download the confirmed cases data and the county population data directly from USAFacts:
cases_raw <- read_csv(
"https://static.usafacts.org/public/data/covid-19/covid_confirmed_usafacts.csv",
show_col_types = FALSE
)
pop_raw <- read_csv(
"https://static.usafacts.org/public/data/covid-19/covid_county_population_usafacts.csv",
show_col_types = FALSE
)Use glimpse() to explore both datasets. The cases data covers every county in the United States — how many rows and columns does it have? What does each row represent? Notice that the cases data is in wide format — each date gets its own column. Why would that be a problem for plotting with ggplot2?
- We only need Kansas. Filter
cases_rawto just Kansas counties (State == "KS") and exclude the statewide total row (countyFIPS != 0). Then usepivot_longer()to reshape the data from wide to long format, so you have one row per county per date with columns forcountyFIPS,County Name,date, andcumulative_cases. Uselubridate::ymd()to parse the date strings into proper Date objects. Do the same filtering forpop_raw— keep only Kansas counties and select justcountyFIPS,County Name, andpopulation.
🧶 ✅ ⬆️ Knit, commit, and push your changes. You’ve acquired and reshaped real web data — just like Holland did!
Part 3: From Cumulative Counts to Daily Rates
You now have cumulative case counts for every Kansas county on every date. But the KDHE visualization shows daily new cases per 100K population as a 7-day rolling average. Getting from what you have to what you need requires several wrangling steps.
- First, narrow the time window. The visualization covers July 12 through August 3, 2020 — but to compute a 7-day rolling average starting on July 12, you need data going back seven days before that. Filter your Kansas cases to dates from July 5, 2020 through August 3, 2020.
Then, within each county (use group_by() and arrange()), calculate daily_new_cases as the difference between each day’s cumulative count and the previous day’s using lag(). Remove the resulting NA rows (the first day of each county has no previous day to subtract from).
Now you need to know which counties had mask mandates. From the MMWR report, you learned that these 24 Kansas counties had mandates in effect by July 3, 2020:
Allen, Atchison, Bourbon, Crawford, Dickinson, Douglas, Franklin, Geary, Gove, Harvey, Jewell, Johnson, Mitchell, Montgomery, Morris, Pratt, Reno, Republic, Saline, Scott, Sedgwick, Shawnee, Stanton, Wyandotte
But there’s a snag — your data has county names like "Sedgwick County" while this list uses just "Sedgwick". Use str_remove() to strip the " County" suffix, then use ifelse() to create a mask_mandate column labeling each county as "Mask" or "No Mask".
Finally, use left_join() to bring in each county’s population from the population data you filtered earlier.
🧶 ✅ ⬆️ Knit, commit, and push your changes. You’ve built an analysis-ready dataset from raw web data!
Part 4: Computing the Rolling Average
You now have daily new cases for each county, labeled by mask mandate status, with population data attached. But the visualization doesn’t show individual counties — it shows aggregate trends for the two groups. Use
group_by(mask_mandate, date)andsummarize()to compute the total new cases and total population for each group on each date. Then:- Calculate the daily rate per 100K:
total_new / total_pop * 100000 - Compute the 7-day rolling average using
zoo::rollmean(per_100k, k = 7, fill = NA, align = "right")(grouped bymask_mandate) - Filter to dates on or after July 12 and drop any
NArolling averages
Use
glimpse()to check your result. You should have three columns —date,rolling_avg, andmask_mandate. Compare your values to thekansas_grouped_rolling_avg.csvfile in the lab repository — they should be very close.- Calculate the daily rate per 100K:
Now use the dataset you just built to reconstruct the misleading visualization. Look carefully at the original — what specific choices make it misleading? (Hint: look at the y-axes. Are they the same? What effect does that have on how the viewer perceives the trends?)
🧶 ✅ ⬆️ Knit, commit, and push your changes. You’ve gone from a press conference screenshot all the way to a reconstructed visualization — all from publicly available web data!
Part 5: Improving the Visualization
Make a visualization that more accurately (and honestly) reflects the data and conveys a clear message.
What message is more clear in your visualization than it was in the original visualization?
What, if any, useful information do these data and your visualization tell us about mask wearing and COVID? It’ll be difficult to set aside what you already know about mask wearing, but you should try to focus only on what this visualization tells. Feel free to also comment on whether that lines up with what you know about mask wearing.
Part 6: Visualization as Rhetoric
Using the same underlying data you recovered, your goal now is to create a new visualization that intentionally conveys the opposite message of your previous, accurate visualization. This exercise is designed to highlight the impact of visualization choices on the interpretation of data.
Reflect on the message conveyed by your accurate visualization regarding mask-wearing and COVID-19. Discuss the key factors that contribute to this message, such as the variables used, the scale of the axes, and the type of visualization.
Plan Your Opposite Visualization: Briefly determine what opposite message you want to convey. Consider the data you have available (or could easily add). For example, you could pull weather data for Kansas during the same time period, using the API we covered in the data acquisition module, and create a visualization that suggests a relationship between weather patterns and COVID-19 cases, rather than mask-wearing.
Use visualization techniques to craft a chart or graph that conveys this contrary perspective. Pay careful attention to how different visualization choices, like altering the y-axis scale or changing the chart type, can influence the message received by the audience.
Stretch Goal: Find and Reconstruct Your Own Misleading Graph
- Now for the real challenge! Find your own misleading graph and try to reconstruct it. You can find misleading graphs in news articles, social media, or even academic papers. Analyze the graph to identify what makes it misleading and then attempt to recreate it using the same data (if available) or similar data. This exercise will help you understand the techniques used to mislead and how to critically evaluate visualizations.
🧶 ✅ ⬆️ Knit, commit, and push your changes to GitHub with an appropriate commit message. Make sure to commit and push all changed files so that your Git pane is cleared up afterwards and review the md document on GitHub to make sure you’re happy with the final state of your work.